


洞察危机:构建高效的系统故障处理方案
在数字化浪潮席卷而来的今天,企业业务对信息系统的依赖程度日益加深。系统的稳定运行是业务连续性的基石,而系统故障,如同潜伏在暗处的“黑天鹅”,一旦发生,轻则影响用户体验,重则导致业务中断,甚至带来不可估量的经济损失和声誉损害。因此,建立一套高效、完善的系统故障处理方案,对于任何一家现代化企业而言,都显得至关重要。
本文将深入剖析一个典型的系统故障处理流程,并在此基础上,为您呈现一份详尽的系统故障处理技术博客,旨在帮助您的团队在面对危机时,能够从容不迫、迅速响应、高效解决,并将每一次故障转化为系统优化的契机。
核心理念:预警、快速响应与持续改进
在深入探讨具体流程之前,我们必须明确系统故障处理的核心理念:
- 预警机制: 防患于未然永远是最佳策略。完善的监控系统和报警机制是发现故障的第一道防线。
- 快速响应: 时间就是金钱,尤其在故障面前。建立明确的责任人、沟通渠道和处理流程,确保故障发生后能以最快速度进入处理环节。
- 持续改进: 每次故障都是一次宝贵的学习机会。通过故障分析报告,总结经验教训,优化流程,提升系统韧性,避免同类问题再次发生。
系统故障处理流程详解
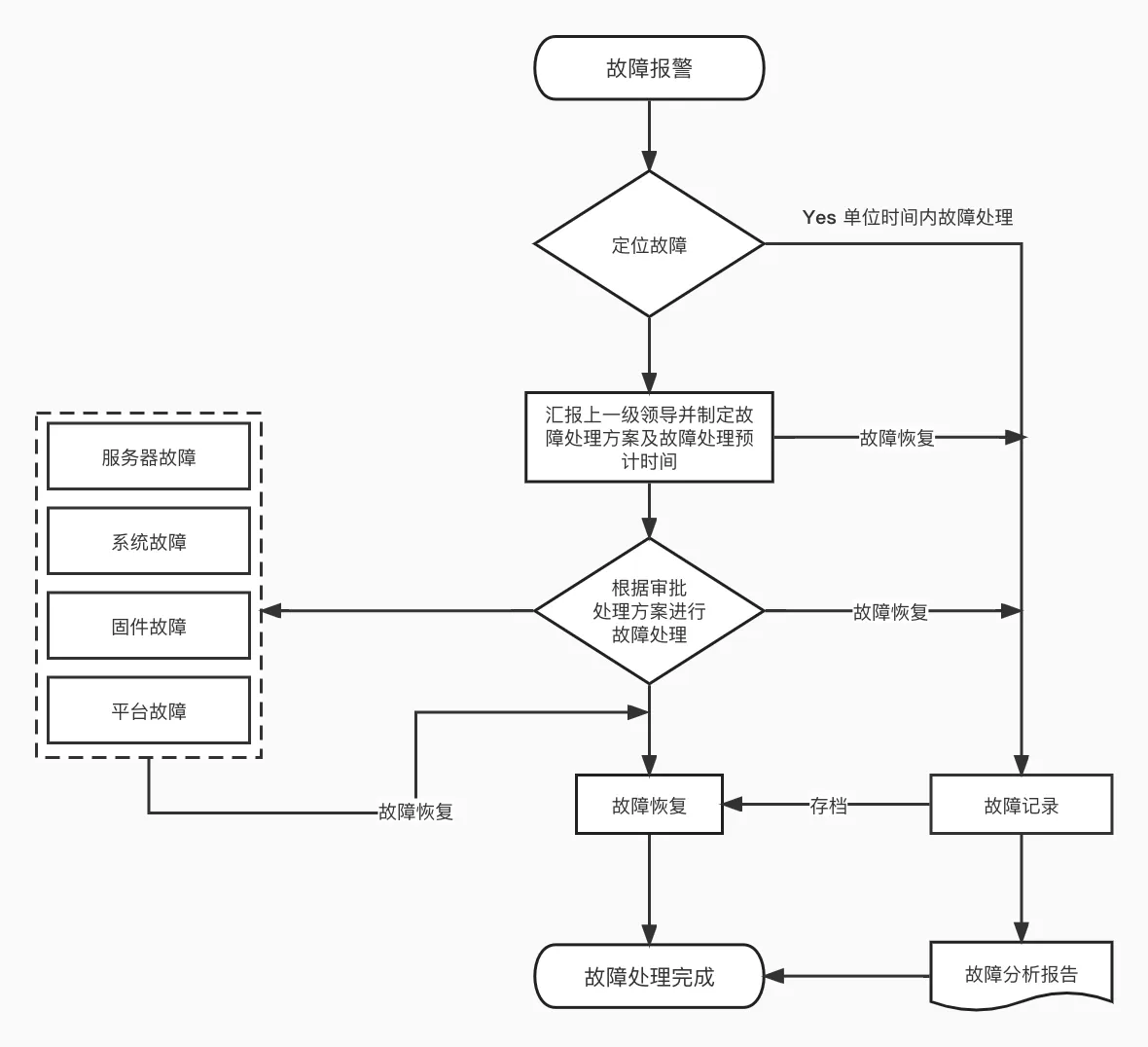
我们参考一个典型的系统故障处理流程图,其核心步骤清晰、逻辑严谨,为我们提供了一个优秀的实践范本。
1. 故障报警:危机的开端
一切的起点是“故障报警”。这可能是由自动化监控系统触发的,例如CPU使用率过高、内存溢出、服务宕机、网络延迟异常等;也可能是由用户反馈、客服上报等人工方式发现的。无论是哪种方式,故障报警都意味着系统状态异常,需要立即引起重视。
技术要点:
- 全面监控: 涵盖服务器、系统、中间件、数据库、网络、应用服务等所有关键组件。
- 多维度报警: 不仅仅是单一阈值报警,应结合趋势分析、异常检测等高级功能。
- 多渠道通知: 电话、短信、邮件、企业IM(如企业微信、钉钉)等多种方式确保通知到相关责任人。
- 报警分级: 根据故障的严重程度和影响范围进行分级,如P0(紧急)、P1(高)、P2(中)、P3(低),不同级别触发不同的响应流程。
2. 定位故障:精准打击的基石
收到报警后,首要任务是“定位故障”。这是一个考验技术人员经验和工具支撑的关键环节。快速准确地定位故障根源,能极大缩短故障恢复时间。
关键步骤:
- 信息收集: 收集报警信息、日志、监控数据、用户反馈等一切有助于定位的资料。
- 初步排查: 根据报警内容和初步分析,判断可能受影响的范围和模块。例如,如果是服务器故障,是硬件问题还是操作系统问题?如果是应用故障,是代码bug还是配置错误?
- Yes/No分支: 流程图中有一个非常重要的分支:“Yes 单位时间内故障处理”。这代表了对故障处理时效性的严格要求。如果故障能在单位时间内(例如SLA规定时间内)被快速定位并处理,则直接进入“故障恢复”阶段。这通常适用于一些常见、有预案的、影响范围较小的故障。
技术要点:
- 日志系统: 集中式日志管理系统(如ELK Stack, Splunk)提供强大的日志检索和分析能力。
- 监控可视化: 仪表盘(如Grafana)能够直观展示系统各项指标,帮助快速发现异常。
- Tracing系统: 分布式追踪系统(如Zipkin, Jaeger)对于微服务架构下的故障定位尤为重要,能追踪请求在各个服务间的调用链。
- 知识库: 积累常见故障的排查手册和解决方案,提升定位效率。
3. 上报与制定方案:集体智慧与预案决策
如果故障无法在单位时间内快速定位和处理(即流程图中的“No”路径),则进入“汇报上一级领导并制定故障处理方案及故障处理预计时间”的环节。这标志着故障的复杂性或严重性超出了基层处理范围,需要更高层级的介入和资源调配。
核心要素:
- 快速上报: 及时向上级领导汇报故障现状、初步判断、已尝试的排查方法以及预计影响。
- 集思广益: 召集相关技术骨干和专家,共同分析故障,制定详细的处理方案。
- 预估时间: 对故障恢复的预计时间进行评估,并告知相关干系人,以便他们采取相应的业务应对措施。
- 考虑因素: 方案制定需考虑故障根源、影响范围、数据一致性、业务连续性等多个方面。例如,是进行服务重启、回滚版本、还是临时扩容?
4. 根据审批处理方案进行故障处理:执行与修正
一旦处理方案获得批准,就进入了“根据审批处理方案进行故障处理”的执行阶段。这是将纸面方案转化为实际行动的关键步骤。
重要考虑:
- 严格遵循方案: 按照既定方案步骤执行,避免盲目操作。
- 操作留痕: 对每一次操作进行记录,包括时间、操作人、操作内容、效果等,以便后续追溯和分析。
- 实时监控: 在处理过程中持续监控系统状态,确保处理操作没有引入新的问题。
- “故障恢复”分支: 无论处理过程中是服务器故障、系统故障、固件故障还是平台故障,只要成功恢复,都直接指向“故障恢复”环节。这表明处理方案是动态的,可能针对不同类型的故障采取不同的处理路径,但最终目标都是恢复系统正常运行。
四种常见故障类型:
- 服务器故障: 硬件层面的问题,如硬盘损坏、电源故障、内存故障、网卡故障等。处理可能涉及硬件更换、RAID重建等。
- 系统故障: 操作系统层面的问题,如系统崩溃、内核死锁、文件系统损坏、驱动问题等。处理可能涉及系统重启、日志分析、补丁安装等。
- 固件故障: 设备固件层面的问题,如BIOS/UEFI固件、网卡固件、存储控制器固件等。处理可能涉及固件升级或回滚。
- 平台故障: 针对虚拟化平台、容器平台(如Kubernetes)、云平台服务等更上层的基础设施问题。处理可能涉及平台组件重启、配置调整、服务迁移等。
5. 故障恢复:胜利的曙光
当系统恢复正常运行,功能和服务恢复可用时,即进入“故障恢复”阶段。
关键动作:
- 验证恢复: 不仅仅是系统启动,还需要通过各种测试(功能测试、性能测试)来验证系统是否完全恢复正常,数据是否完整一致。
- 通知与确认: 通知相关干系人(包括业务部门、用户)故障已解决,并确认业务是否恢复正常。
6. 故障记录与故障分析报告:经验的沉淀
故障恢复后,工作并未结束。接下来是“故障记录”和“故障分析报告”的环节,这是将每一次危机转化为成长机会的关键步骤。
- 故障记录: 详细记录故障发生的时间、发现方式、故障现象、影响范围、处理过程、恢复时间、处理人、使用的工具等所有相关信息。这为后续的分析提供了第一手资料,并且是构建故障知识库的重要组成部分。
- 故障分析报告: 这是对故障进行深入剖析的文档。其内容应包括:
- 故障概述: 简单描述故障发生情况。
- 故障时间线: 从发现到恢复的详细时间轴。
- 故障现象: 详细描述用户端和系统端的表现。
- 故障定位过程: 如何一步步找到故障根源。
- 故障根本原因(Root Cause): 重点!这是最关键的部分,需要深入分析,是代码bug、配置错误、硬件故障、网络问题、操作失误、还是设计缺陷?
- 处理过程: 详细记录采取了哪些措施,效果如何。
- 经验教训: 从本次故障中学习到了什么?
- 改进措施: 针对故障根本原因提出具体的改进方案,包括技术改进(如代码优化、架构调整、监控增强)、流程改进(如审批流程、应急演练)、人员培训等。这些措施是避免同类故障再次发生的保障。
技术要点:
- 知识库系统: 将故障记录和分析报告录入统一的知识库,方便后续检索和学习。
- RCA(Root Cause Analysis)方法: 运用如5 Whys、鱼骨图等方法深入挖掘故障根本原因。
7. 故障处理完成:一个阶段的结束
当故障分析报告完成并通过评审后,整个“故障处理”流程才算真正“完成”。这标志着从发现问题到解决问题再到总结经验、制定改进措施的全闭环流程的完成。
构建高可用系统的关键实践
除了上述流程,以下几点是构建高可用系统不可或缺的关键实践:
- 容灾与备份: 建立完善的数据备份和恢复机制,以及异地容灾方案,确保在极端故障情况下业务数据不丢失,并能快速恢复服务。
- 自动化运维: 尽可能将重复性的运维操作自动化,减少人为失误,提高效率。例如,自动化部署、自动化扩缩容、自动化健康检查。
- 灰度发布与A/B测试: 在生产环境中逐步发布新功能或新版本,通过灰度发布和A/B测试,及时发现潜在问题,降低故障风险。
- 混沌工程: 主动向系统注入故障,模拟真实世界的各种异常情况,以发现系统弱点,提升系统韧性。
- 定期演练: 定期进行故障演练,模拟各种故障场景,检验团队的响应能力和预案的有效性。
- SLA与MTTR/MTBF: 定义清晰的服务等级协议(SLA),并关注平均故障恢复时间(MTTR)和平均故障间隔时间(MTBF)等指标,持续优化。MTTR越短越好,MTBF越长越好。
结语
系统故障是不可避免的,但我们可以通过建立一套完善、高效的故障处理方案,将故障的影响降到最低,并从中汲取经验,不断提升系统的韧性和稳定性。从故障报警到定位,从方案制定到执行,再到最后的故障分析报告,每一步都凝聚着技术团队的智慧和努力。只有将每一次故障都视为一次宝贵的学习机会,我们才能在不断变化的技术环境中,为业务提供更可靠、更稳定的技术支撑,最终实现企业的可持续发展。


评论区