


Flink 3种部署模式、保证高可用的区别/Standalone Cluster/Yarn Cluster /Kubernetes Cluster

Standalone Cluster
该模式下,作业共享集群资源,作业通过Http协议进行提交。
在Flink 1.10版本中提供了3种会话模式:Yarn会话模式、K8s会话模式、Standalone。Standalone模式比较特别,Flink安装在物理机上,不能像在资源集群上一样,可以随时启动一个新集群,所有的作业共享Standalone集群,本质上就是一种Session模式,所以不支持Per-Job模式。
在Session模式下,Yarn作业提交使用yarn-session.sh脚本,K8s作业提交使用kubernetes-session.sh脚本。两者的具体实现不同,但逻辑是类似的,在启动脚本的时候就会检查是否存在已经启动好的Flink Session模式集群,如果没有,则启动一个Flink Session模式集群,然后在PipelineExecutor中,通过Dispatcher提供的Rest接口提交JobGraph,Dispatcher为每个作业启动一个JobMaster,进入作业执行阶段。
Master-Slave架构
JobManager运行在Master节点,TaskManager运行在Slave节点,与HDFS/Hadoop无关.
Active JobManager挂掉时,通过Zookeeper选举多个Standby JobManager成为Active JobManager来保证高可用
Yarn Cluster
Yarn Session模式
在YARN之上部署了Flink Session集群(可屏蔽底层不同的运行环境),向Yarn Session集群提交作业(不与YARN交互),多个作业共用集群资源(一个JobManager管理多个作业,作业越多则JobManager的负载越大),JobManager挂掉时会通过重启来保证高可用
Single Job模式
作业直接提交到YARN上(与YARN交互),一个作业对应一个JobManager,资源隔离,
Kubernetes Cluster :
Session模式
Session模式是预分配资源的,也就是提前根据指定的资源参数初始化一个Flink集群,并常驻在YARN系统中,拥有固定数量的JobManager和TaskManager(注意JobManager只有一个)。提交到这个集群的作业可以直接运行,免去每次分配资源的overhead。但是Session的资源总量有限,多个作业之间又不是隔离的,故可能会造成资源的争用;如果有一个TaskManager宕机,它上面承载着的所有作业也都会失败。另外,启动的作业越多,JobManager的负载也就越大。所以,Session模式一般用来部署那些对延迟非常敏感但运行时长较短的作业。
Per-Job模式
顾名思义,在Per-Job模式下,每个提交到YARN上的作业会各自形成单独的Flink集群,拥有专属的JobManager和TaskManager。可见,以Per-Job模式提交作业的启动延迟可能会较高,但是作业之间的资源完全隔离,一个作业的TaskManager失败不会影响其他作业的运行,JobManager的负载也是分散开来的,不存在单点问题。当作业运行完成,与它关联的集群也就被销毁,资源被释放。所以,Per-Job模式一般用来部署那些长时间运行的作业。
该模式下,一个作业一个集群,作业之间相互隔离。在Flink 1.10版本中,只有Yarn上实现了Per-Job模式,K8s的Per-Job模式在后续版本中会实现。Per-Job模式下,因为不需要共享集群,所以在PipelineExecutor中执行作业提交的时候,可以创建集群并将JobGraph以及所需要的文件等一同提交给Yarn集群,Yarn集群在容器中启动Flink Master进程(即JobManager进程),进行一系列的初始化动作,初始化完毕之后,从文件系统中获取JobGraph,交给Dispatcher。之后的执行流程与Session模式下的执行流程相同。
Application Mode
但是现在这些平台遇到一个大问题是部署服务是一个消耗资源比较大的服务,并且很难计算出实际资源限制。比如,如果我们取负载的平均值,则可能导致部署服务的资源真实所需的值远远大于限制值,最坏的情况是在一定时间影响所有的线上应用。但是如果我们将取负载的最大值,又会造成很多不必要的浪费。基于此,Flink 1.11 引入了另外一种部署选项 Application Mode, 该模式允许更加轻量级,可扩展的应用提交进程,将之前客户端的应用部署能力均匀分散到集群的每个节点上。
存在的问题
上文所述Session模式和Per-Job模式可以用如下的简图表示,其中红色、蓝色和绿色的图形代表不同的作业。
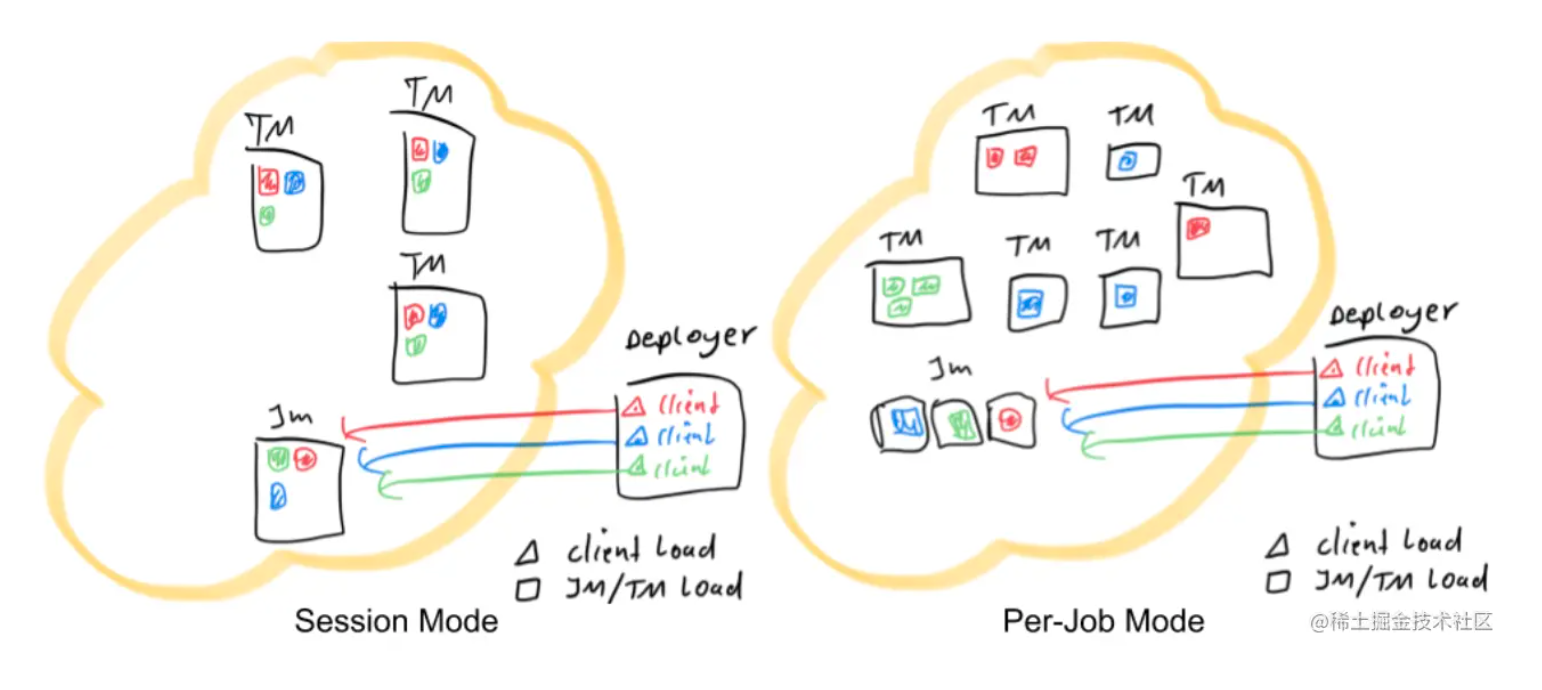
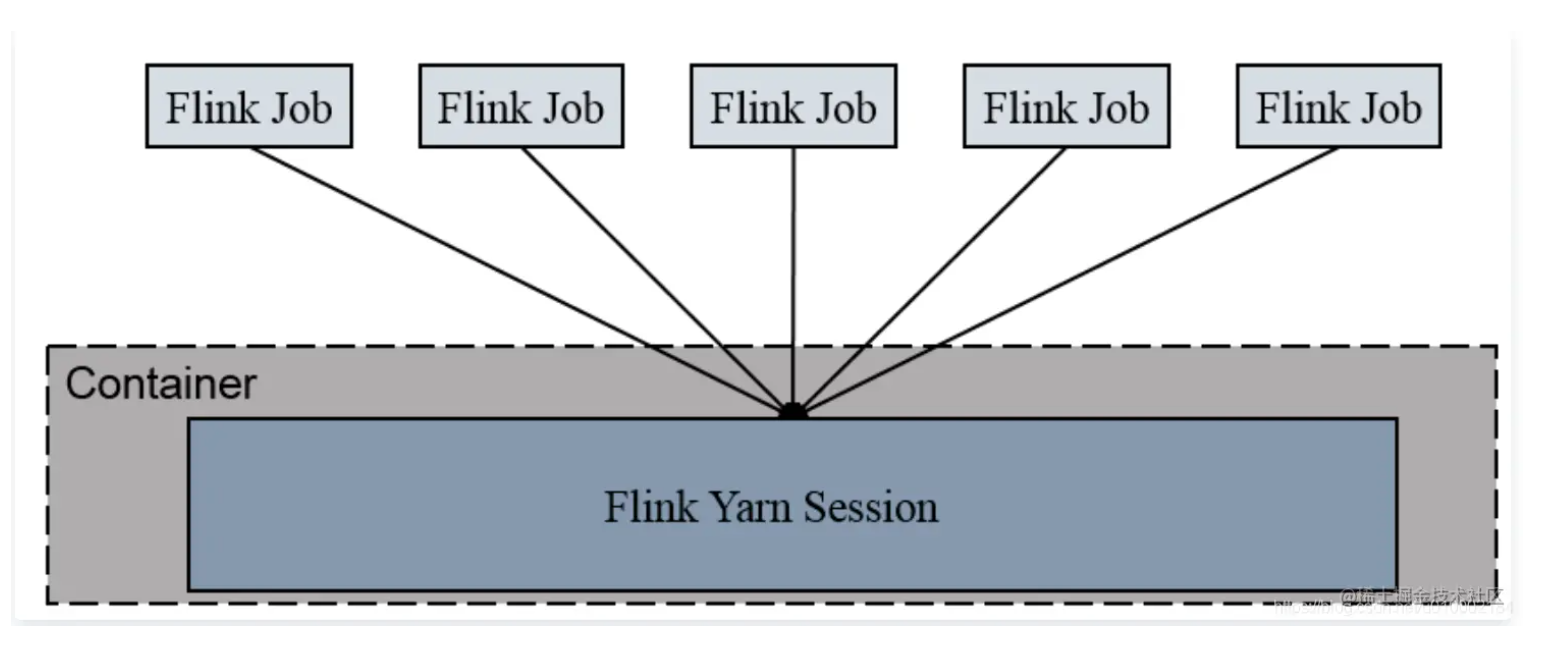
Session-Cluster模式
Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。
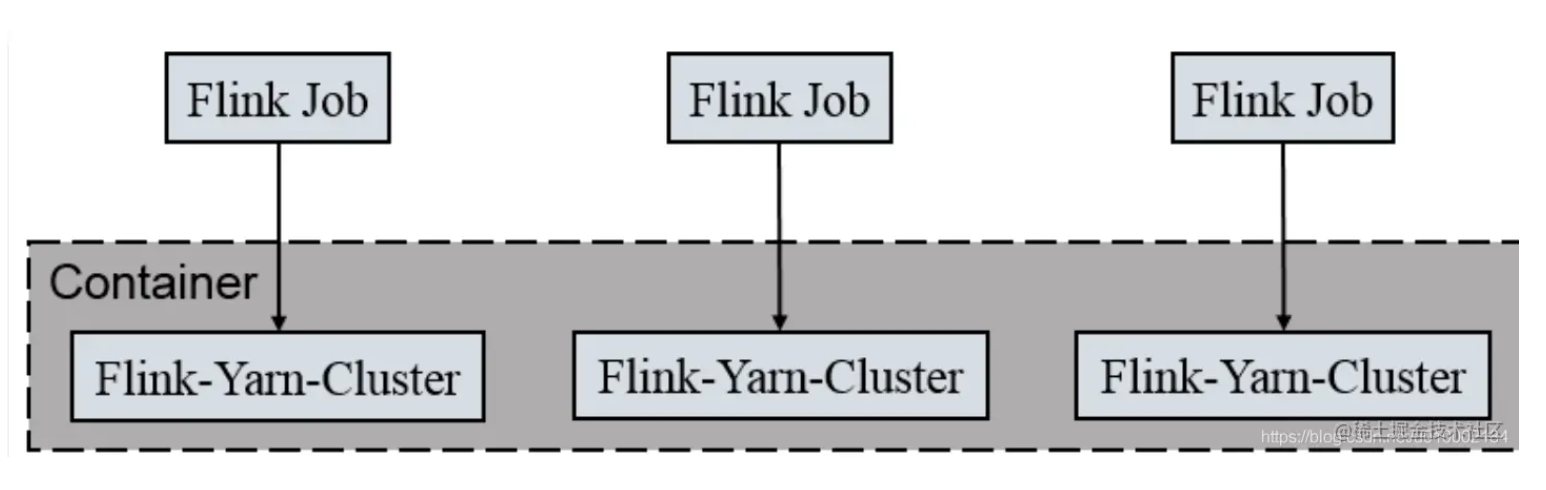
Per-Job-Cluster模式
一个任务会对应一个Job,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。


评论区