


ETCD连接报错:database space exceeded

一:背景#
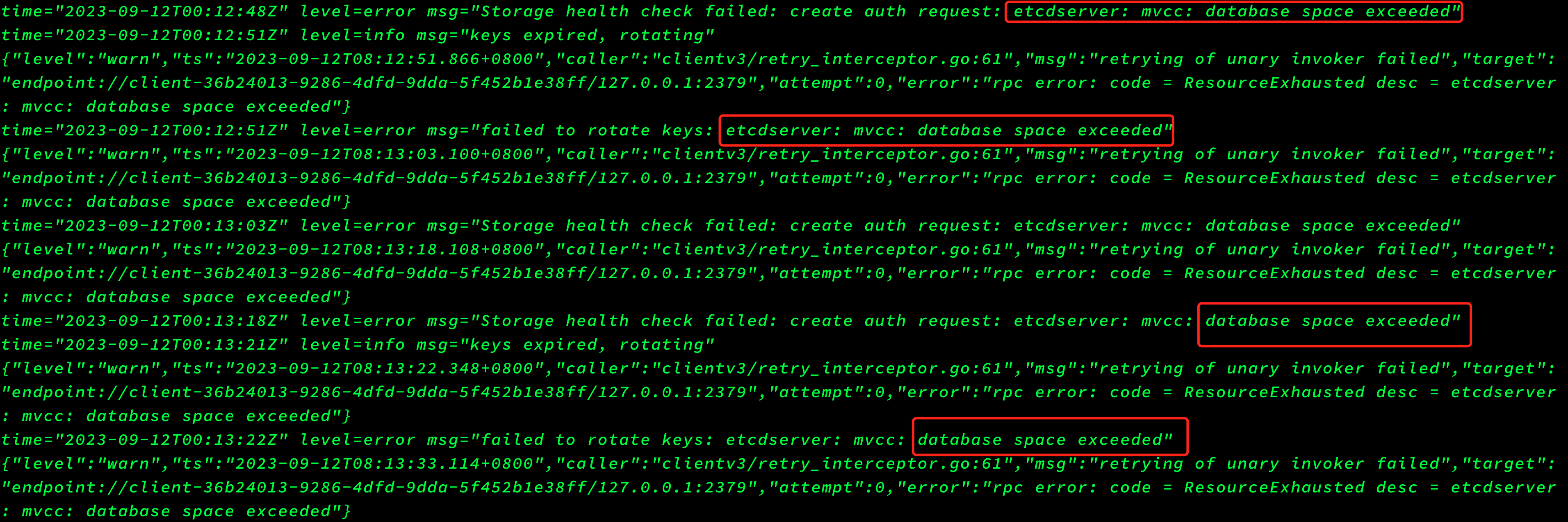
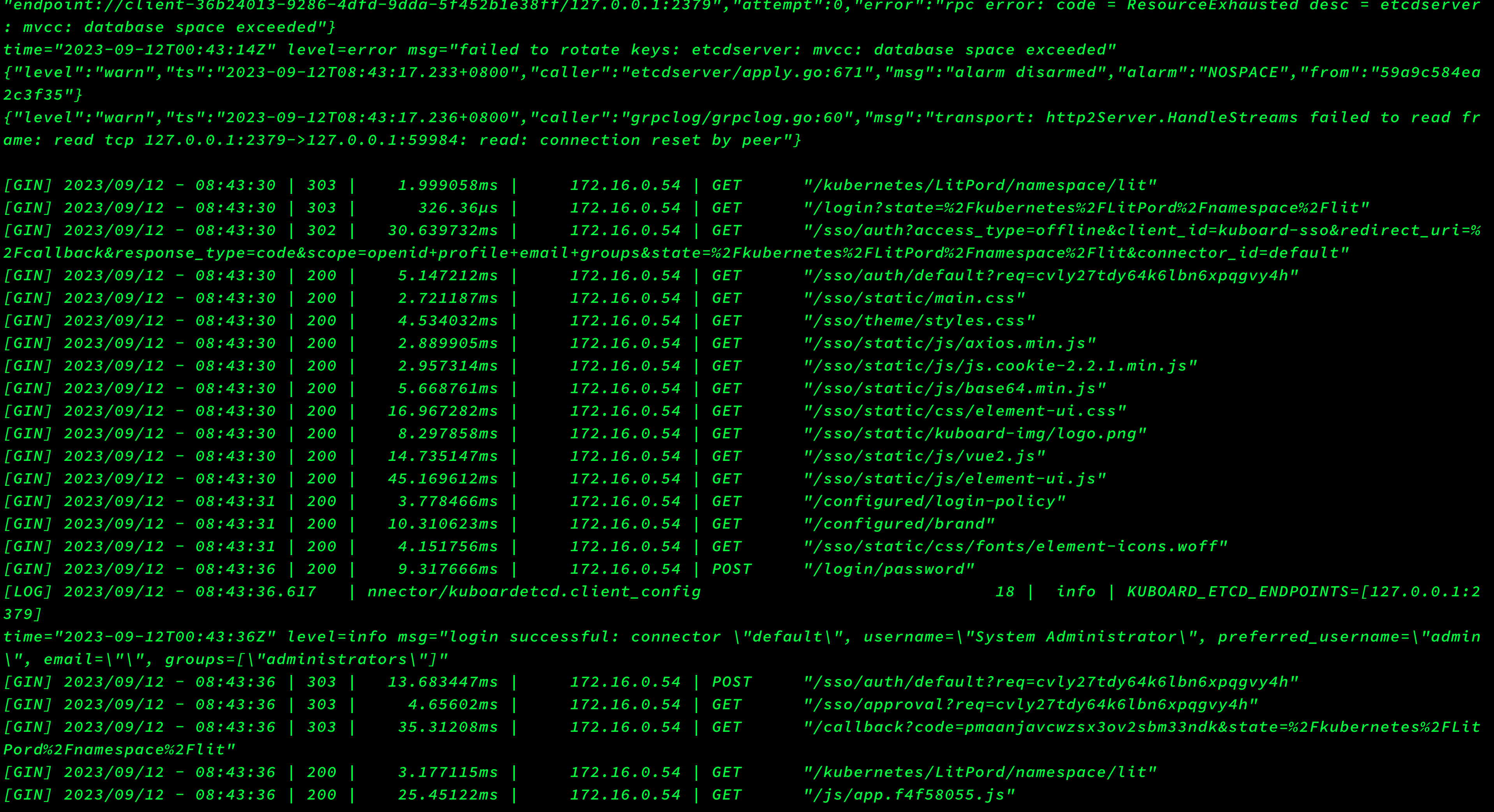
此etcd不是k8s集群中的etcd,是kuboard中使用etcd报错,kuboard稳定运行了一年多,上周还正常访问,今天上班访问kuboard报错,然后顺着排查发现kuboard中使用了etcd(之前一直没注意),查看kuboard日志,发现如下报错信息:
二:报错分析:#
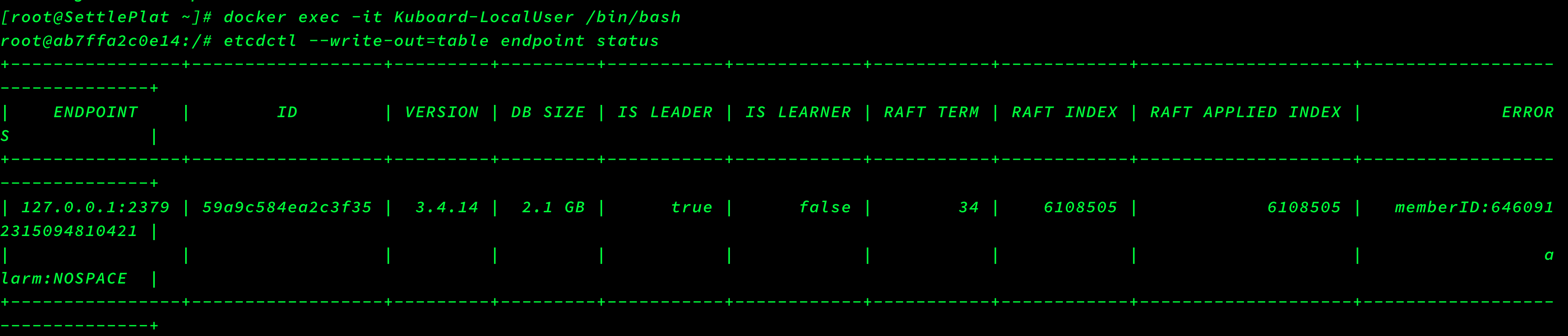
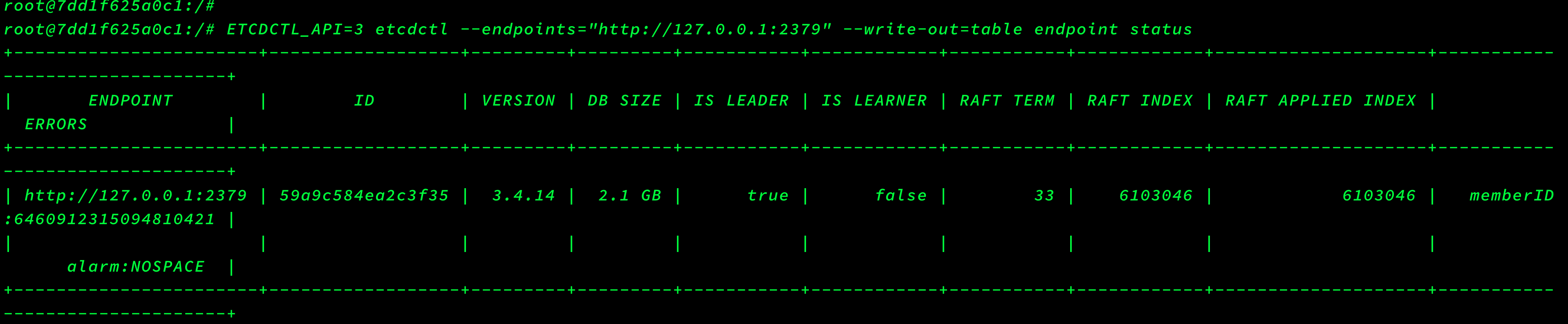
大致意思就是kuboard服务连接ETCD数据库失败,然后复制重点报错信息去google:etcd “database space exceeded”,查看了几个网页聚合后得到的信息大致为ETCD存储满了,最开始我以为是ETCD存储的磁盘满了,登陆ETCD服务器df -h后发现空间很充足,然后继续google,发现etcd为了保证性能,设置了空间配额,空间配额默认值(–quota-backend-bytes)为2G,详情见此官方文档和此官方博客,然后通过:etcdctl --write-out=table endpoint status或者ETCDCTL_API=3 etcdctl --endpoints="http://127.0.0.1:2379" --write-out=table endpoint status命令查看节点信息如下,发现DB SIZE 已经为2.1G了,默认空间配额为2G, 这里DB SIZE已经超过2G,触发ETCD维护模式,只能进行读和删除操作。包括ERRORS行也告警NOSPACE。
三:解决问题#
- etcd备份(自行google,此处不叙述)
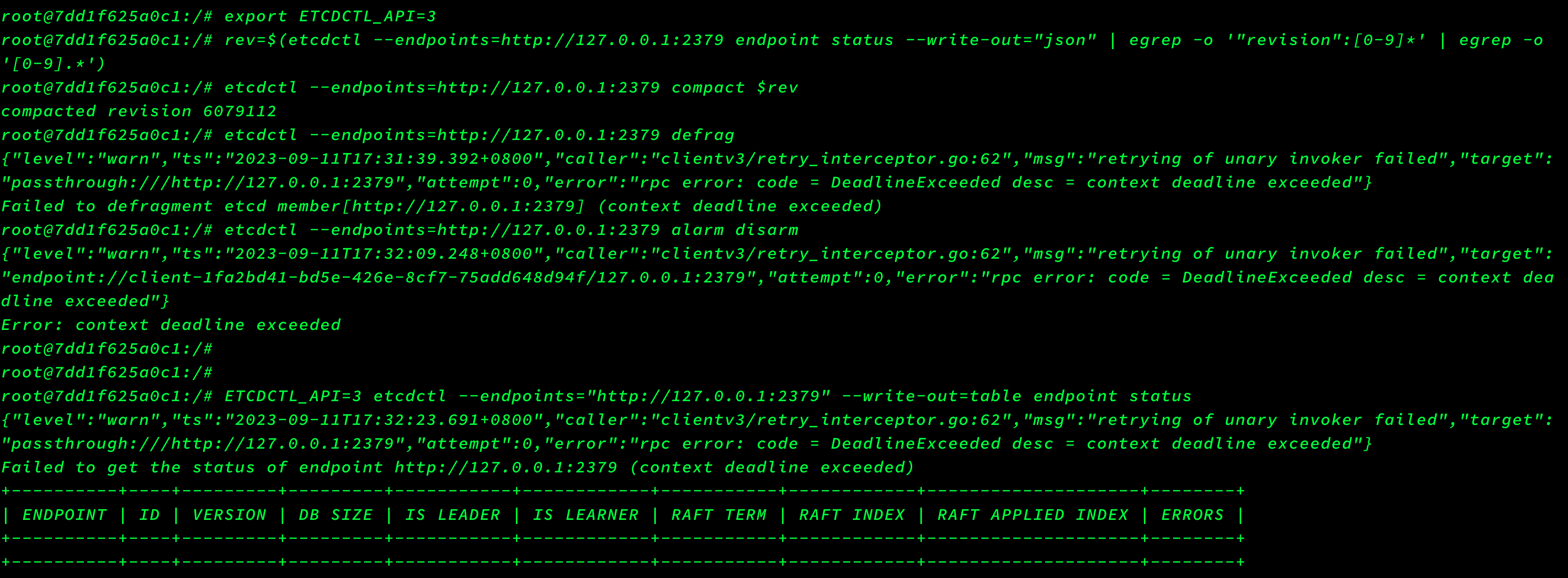
- 获取当前版本
rev=$(etcdctl endpoint status -w json | egrep -o '"revision":[0-9]*' | egrep -o '[0-9]*'| awk 'NR==1{print $1}')
- 压缩掉所有旧版本;再次压缩时会报错,因为之前已经压缩过。
etcdctl compact $rev
#或者
etcdctl --endpoints=http://127.0.0.1:2379 compact $rev

- 清理碎片
etcdctl defrag

- 再次查看节点信息,此时DB SIZE已清理完成,但是告警还在,ETCD还处于维护模式。
etcdctl endpoint status -w table

- 解除告警,然后再次查看节点信息,告警也消失了
etcdctl alarm disarm

- 查看容器日志已经正常
参考链接:https://www.cnblogs.com/ltzhang/p/14316009.html
ETCD
root@7dd1f625a0c1:/# which etcdctl
/usr/bin/etcdctl
root@7dd1f625a0c1:/# ETCDCTL_API=3 etcdctl --endpoints="http://127.0.0.1:2379" --write-out=table endpoint status
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
|---|---|---|---|---|---|---|---|---|---|
| http://127.0.0.1:2379 | 59a9c584ea2c3f35 | 3.4.14 | 2.1 GB | true | false | 33 | 6103046 | 6103046 | memberID:6460912315094810421 |
root@7dd1f625a0c1:/# export ETCDCTL_API=3
root@7dd1f625a0c1:/# rev=$(etcdctl --endpoints=http://127.0.0.1:2379 endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*')
root@7dd1f625a0c1:/# etcdctl --endpoints=http://127.0.0.1:2379 compact $rev
compacted revision 6079112
root@7dd1f625a0c1:/# etcdctl --endpoints=http://127.0.0.1:2379 defrag
{"level":"warn","ts":"2023-09-11T17:31:39.392+0800","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"passthrough:///http://127.0.0.1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Failed to defragment etcd member[http://127.0.0.1:2379] (context deadline exceeded)
root@7dd1f625a0c1:/# etcdctl --endpoints=http://127.0.0.1:2379 alarm disarm
{"level":"warn","ts":"2023-09-11T17:32:09.248+0800","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"endpoint://client-1fa2bd41-bd5e-426e-8cf7-75add648d94f/127.0.0.1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Error: context deadline exceeded
root@7dd1f625a0c1:/#
root@7dd1f625a0c1:/#
root@7dd1f625a0c1:/# ETCDCTL_API=3 etcdctl --endpoints="http://127.0.0.1:2379" --write-out=table endpoint status
{"level":"warn","ts":"2023-09-11T17:32:23.691+0800","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"passthrough:///http://127.0.0.1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Failed to get the status of endpoint http://127.0.0.1:2379 (context deadline exceeded)


评论区