


BMR

Hadoop
version
- 查看版本信息
sudo -u hdfs hadoop version
ls
- 查看HDFS文件信息
sudo -u hdfs hadoop fs -ls / 查看根目录下的文件
ls -R
- 递归查看某个目录的所有子文件
sudo -u hdfs hadoop fs -ls -R /hdp/apps/
mkdir
- 新建目录
hadoop fs -mkdir /testdir001
实验没成功,提示权限问题。
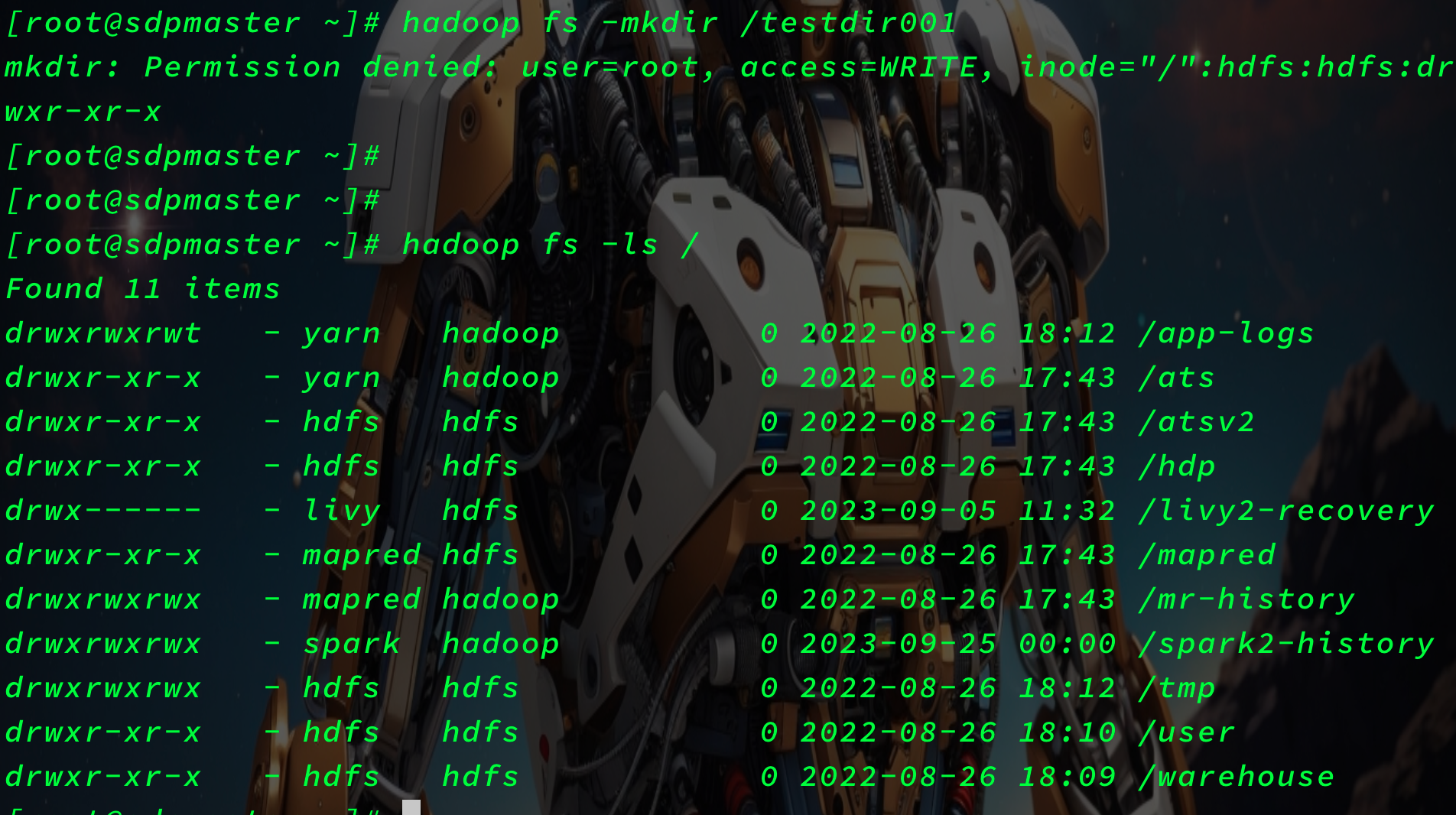
变更用户后使用Hadoop的超级用户'hdfs'后执行就成功了,命令如下:
sudo -u hdfs hadoop fs -mkdir /testdir001

copyFromLocal
- 上传文件到HDFS目录下
hadoop fs -copyFromLocal /root/get.tar /tmp/
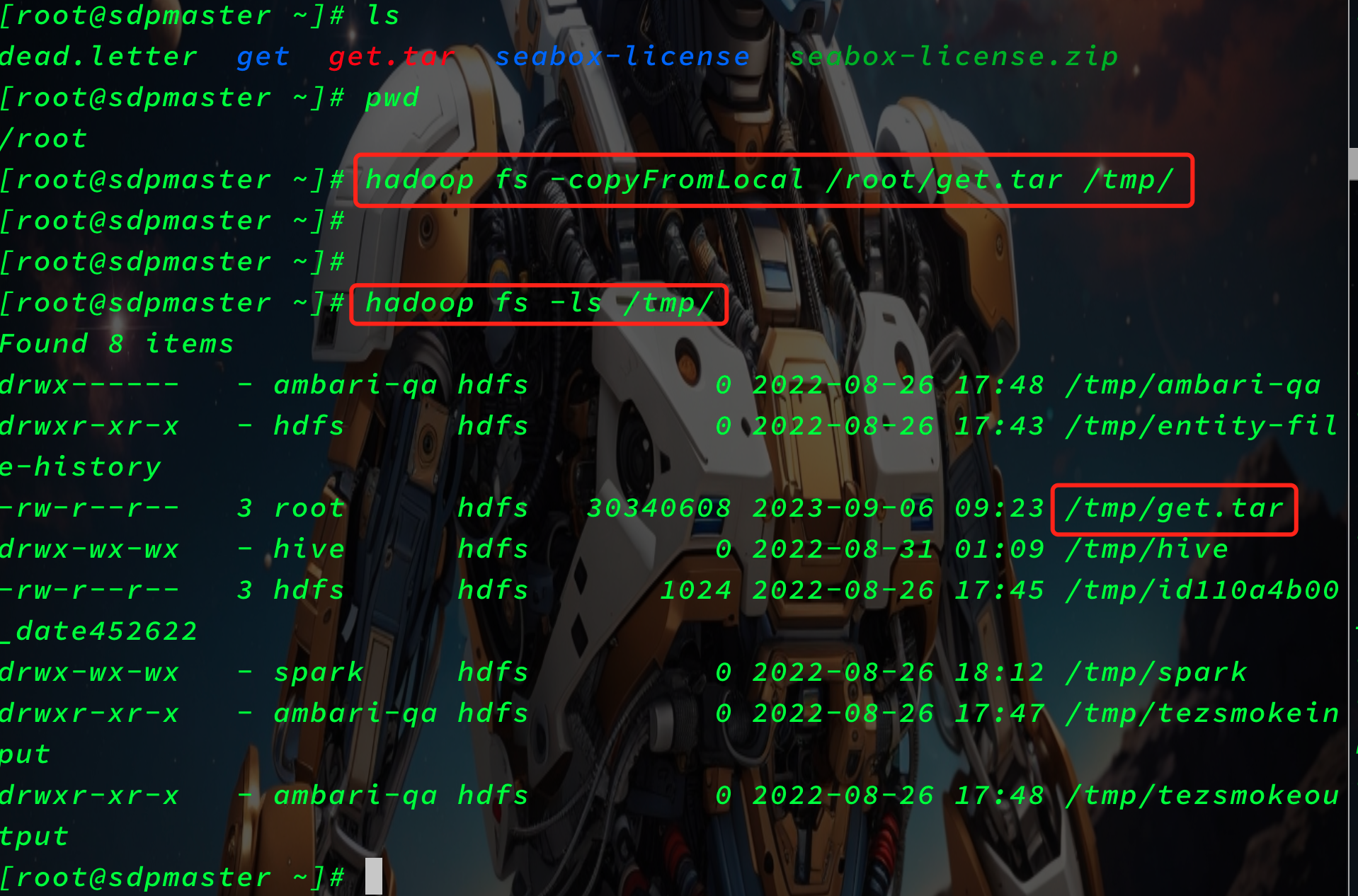
copyToLocal
- 下载文件到本地
hadoop fs -copyToLocal /tmp/spark /root/HDFS_Download
cat
- 查看文件内容
hadoop fs -cat /tmp/spark.txt
cp
- HDFS系统内文件复制
hadoop fs -cp /tmp/spark.txt /hdp/apps/spark.txt
get
- 直接下载了
hadoop fs -get /tmp/spark.txt
-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>
put
-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>
mv
rm
du
fsck
- 检查根目录 '/' 的文件系统状态
sudo -u hdfs hadoop fsck /

jar
jar <jar> run a jar file. NOTE: please use "yarn jar" to launch YARN applications, not this command.
hadoop jar /usr/local/1.2.0/hadoop-mapreduce-examples-3.1.1.jar wordcount /testdir001 /testdir001/output
这条命令是一个Hadoop MapReduce作业的启动命令,用于运行一个叫做"wordcount"的示例MapReduce作业。让我逐步解释这个命令的各个部分:
hadoop jar:这是命令的开始,它告诉Hadoop要运行一个Java JAR文件,并将其解释为一个MapReduce作业。在这里,hadoop是Hadoop命令行工具,jar表示要运行一个Java归档文件。
/usr/local/1.2.0/hadoop-mapreduce-examples-3.1.1.jar:这是要运行的Java JAR文件的路径。在这个例子中,它是Hadoop发行版的一部分,包含了一些示例MapReduce作业,其中包括了"wordcount"作业。
wordcount:这是要运行的MapReduce作业的类名。在Hadoop示例中,"wordcount"是一个非常常见的示例作业,用于计算文本文件中每个单词的出现次数。
/testdir001:这是输入数据的Hadoop文件系统路径。MapReduce作业将从这个目录中的文件读取数据,然后执行"wordcount"操作。
/testdir001/output:这是输出结果的Hadoop文件系统路径。MapReduce作业将计算"wordcount"并将结果写入这个目录。
综合起来,这个命令的作用是运行一个名为"wordcount"的MapReduce作业,该作业从/testdir001目录中的文件读取数据,并将结果写入/testdir001/output目录中。这是一个常见的示例,用于演示如何使用Hadoop来处理和分析大规模的文本数据,特别是计算每个单词在文本中出现的次数。
distcp
- Hadoop分布式复制(distcp)命令
hadoop distcp /testdir001 /testdir004
这条命令是Hadoop分布式复制(distcp)命令的示例,用于将数据从一个Hadoop文件系统路径复制到另一个Hadoop文件系统路径。让我逐步解释这个命令的各个部分:
hadoop distcp:这是命令的开始,它告诉Hadoop要执行分布式复制操作。
/testdir001:这是源目录,也就是要复制数据的目录。在这个例子中,数据将从/testdir001目录中复制出来。
/testdir004:这是目标目录,也就是将数据复制到的目录。在这个例子中,数据将被复制到/testdir004目录中。
综合起来,这个命令的作用是将/testdir001目录中的数据复制到/testdir004目录中。这是一个用于在Hadoop集群内进行数据迁移、备份或复制的常见命令。分布式复制(distcp)命令可以高效地处理大规模数据的复制操作,充分利用Hadoop集群的分布式特性,以提高性能和可伸缩性。
job -status
hadoop job -status application_168708787897_003
Application_xxxxxx_xx 是在HadoopWebUI中获取到的。
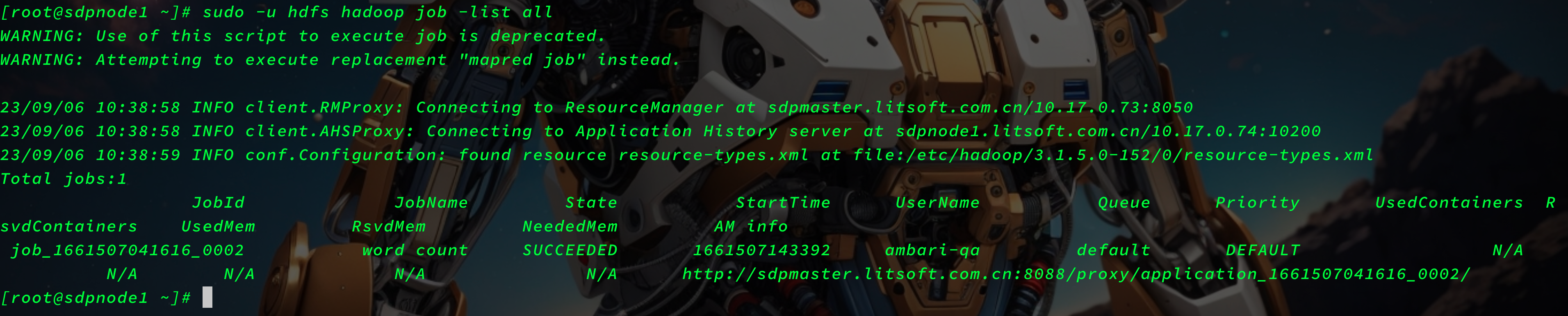
job -list all
sudo -u hdfs hadoop job -list all
dfsadmin -report
sudo -u hdfs hadoop dfsadmin -report
- 查看报告状态
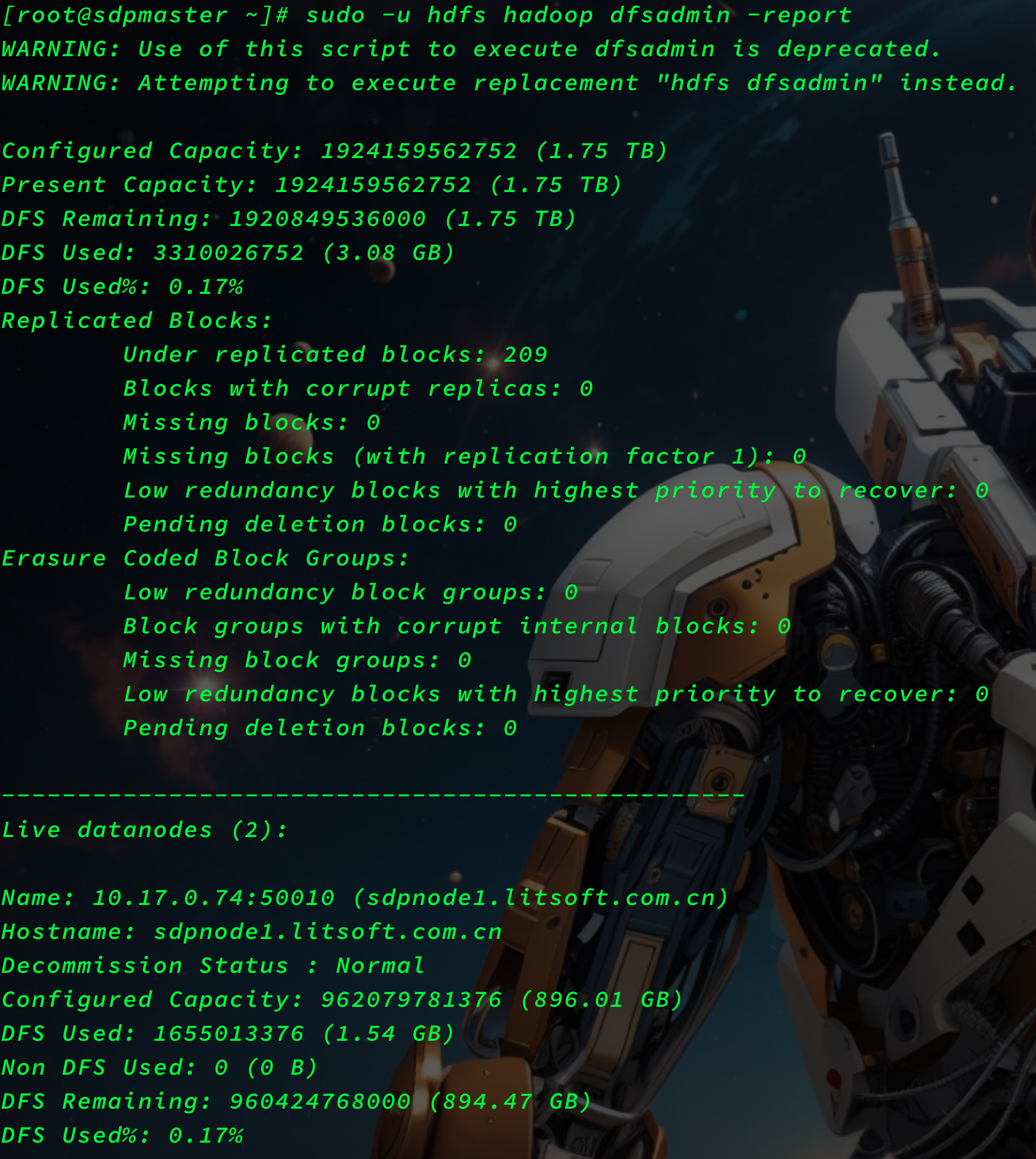

[root@sdpmaster ~]# sudo -u hdfs hadoop dfsadmin -report
WARNING: Use of this script to execute dfsadmin is deprecated.
WARNING: Attempting to execute replacement "hdfs dfsadmin" instead.
Configured Capacity: 1924159562752 (1.75 TB)
Present Capacity: 1924159562752 (1.75 TB)
DFS Remaining: 1920849536000 (1.75 TB)
DFS Used: 3310026752 (3.08 GB)
DFS Used%: 0.17%
Replicated Blocks:
Under replicated blocks: 209
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 10.17.0.74:50010 (sdpnode1.litsoft.com.cn)
Hostname: sdpnode1.litsoft.com.cn
Decommission Status : Normal
Configured Capacity: 962079781376 (896.01 GB)
DFS Used: 1655013376 (1.54 GB)
Non DFS Used: 0 (0 B)
DFS Remaining: 960424768000 (894.47 GB)
DFS Used%: 0.17%
DFS Remaining%: 99.83%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Wed Sep 06 10:45:58 CST 2023
Last Block Report: Wed Sep 06 09:33:49 CST 2023
Num of Blocks: 209
Name: 10.17.0.75:50010 (sdpnode2.litsoft.com.cn)
Hostname: sdpnode2.litsoft.com.cn
Decommission Status : Normal
Configured Capacity: 962079781376 (896.01 GB)
DFS Used: 1655013376 (1.54 GB)
Non DFS Used: 0 (0 B)
DFS Remaining: 960424768000 (894.47 GB)
DFS Used%: 0.17%
DFS Remaining%: 99.83%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Wed Sep 06 10:45:59 CST 2023
Last Block Report: Wed Sep 06 08:30:43 CST 2023
Num of Blocks: 209
Dead datanodes (1):
Name: 10.17.0.73:50010 (sdpmaster.litsoft.com.cn)
Hostname: sdpmaster.litsoft.com.cn
Decommission Status : Normal
Configured Capacity: 962079781376 (896.01 GB)
DFS Used: 1628323890 (1.52 GB)
Non DFS Used: 0 (0 B)
DFS Remaining: 960317241079 (894.37 GB)
DFS Used%: 0.17%
DFS Remaining%: 99.82%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Tue Sep 05 10:56:03 CST 2023
Last Block Report: Tue Sep 05 10:54:53 CST 2023
Num of Blocks: 0
Dfsadmin -safemode
sudo -u hdfs hadoop dfsadmin -safemode enter
Usage: hdfs dfsadmin [-safemode enter | leave | get | wait | forceExit]


Yarn
version
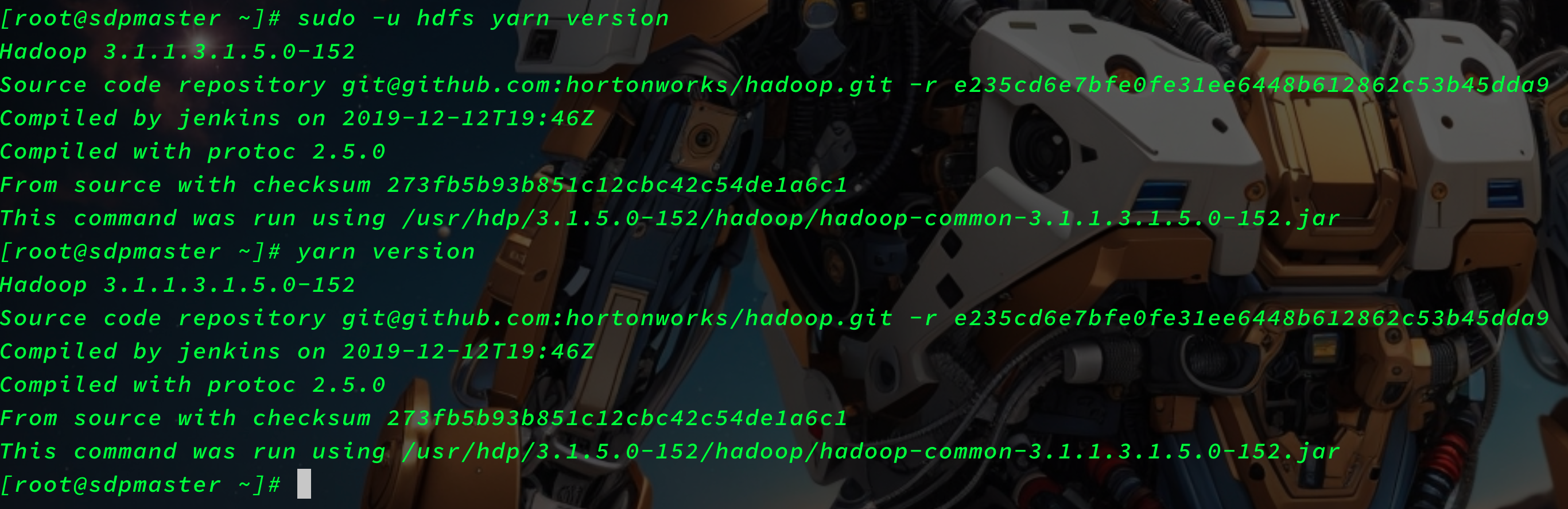
application -list
yarn application -list

application -list -appStates RUNNING
yarn application -list -appStates RUNNING

Kill
yarn application -kill ${Application-Id}

Logs
node -list
yarn node -list

Queue
yarn queue -status root

Hive
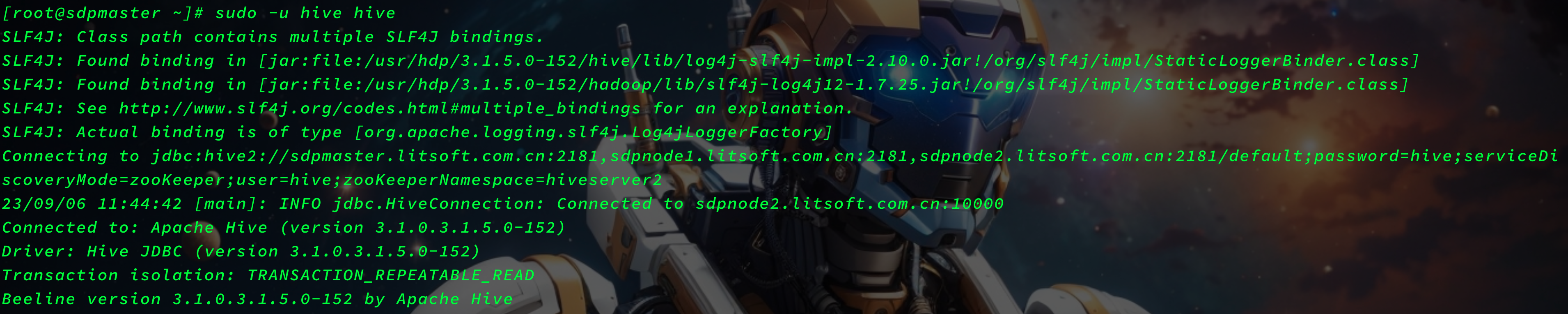
hive
sudo -u hive hive
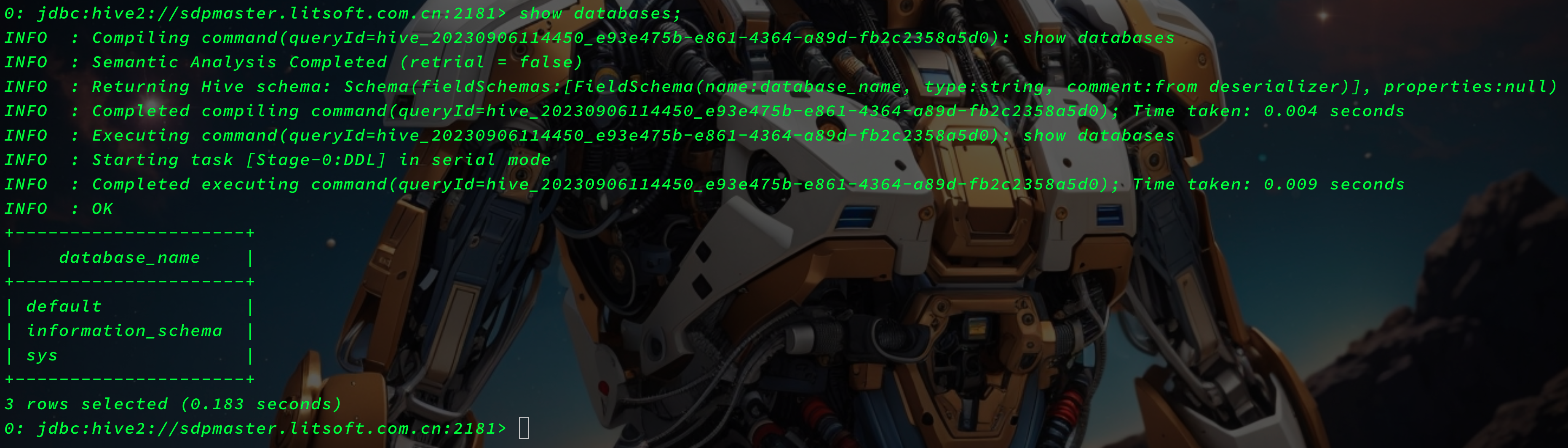
0: jdbc:hive2://sdpmaster.litsoft.com.cn:2181> use sys;
INFO : Compiling command(queryId=hive_20230906114933_37c568e8-f94a-4e09-acf6-8677eaaf6521): use sys
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=hive_20230906114933_37c568e8-f94a-4e09-acf6-8677eaaf6521); Time taken: 0.011 seconds
INFO : Executing command(queryId=hive_20230906114933_37c568e8-f94a-4e09-acf6-8677eaaf6521): use sys
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hive_20230906114933_37c568e8-f94a-4e09-acf6-8677eaaf6521); Time taken: 0.013 seconds
INFO : OK
No rows affected (0.043 seconds)
0: jdbc:hive2://sdpmaster.litsoft.com.cn:2181> show tables;
INFO : Compiling command(queryId=hive_20230906114937_38a441a5-b9c6-4f1f-a1eb-88e3baa91958): show tables
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hive_20230906114937_38a441a5-b9c6-4f1f-a1eb-88e3baa91958); Time taken: 0.012 seconds
INFO : Executing command(queryId=hive_20230906114937_38a441a5-b9c6-4f1f-a1eb-88e3baa91958): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hive_20230906114937_38a441a5-b9c6-4f1f-a1eb-88e3baa91958); Time taken: 0.017 seconds
INFO : OK
+----------------------------+
| tab_name |
+----------------------------+
| bucketing_cols |
| cds |
| columns_v2 |
| database_params |
| db_privs |
| db_version |
| dbs |
| funcs |
| global_privs |
| key_constraints |
| mv_creation_metadata |
| mv_tables_used |
| part_col_privs |
| part_col_stats |
| part_privs |
| partition_key_vals |
| partition_keys |
| partition_params |
| partition_stats_view |
| partitions |
| role_map |
| roles |
| sd_params |
| sds |
| sequence_table |
| serde_params |
| serdes |
| skewed_col_names |
| skewed_col_value_loc_map |
| skewed_string_list |
| skewed_string_list_values |
| skewed_values |
| sort_cols |
| tab_col_stats |
| table_params |
| table_stats_view |
| tbl_col_privs |
| tbl_privs |
| tbls |
| version |
| wm_mappings |
| wm_pools |
| wm_pools_to_triggers |
| wm_resourceplans |
| wm_triggers |
+----------------------------+
45 rows selected (0.059 seconds)
0: jdbc:hive2://sdpmaster.litsoft.com.cn:2181> desc version;
INFO : Compiling command(queryId=hive_20230906114947_f34c651f-cc28-429f-8d86-2a797ce85f2f): desc version
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col_name, type:string, comment:from deserializer), FieldSchema(name:data_type, type:string, comment:from deserializer), FieldSchema(name:comment, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hive_20230906114947_f34c651f-cc28-429f-8d86-2a797ce85f2f); Time taken: 0.115 seconds
INFO : Executing command(queryId=hive_20230906114947_f34c651f-cc28-429f-8d86-2a797ce85f2f): desc version
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hive_20230906114947_f34c651f-cc28-429f-8d86-2a797ce85f2f); Time taken: 0.026 seconds
INFO : OK
+------------------+------------+----------+
| col_name | data_type | comment |
+------------------+------------+----------+
| ver_id | int | |
| schema_version | string | |
| version_comment | string | |
+------------------+------------+----------+
3 rows selected (0.224 seconds)
0: jdbc:hive2://sdpmaster.litsoft.com.cn:2181> select * from version limit 1;
INFO : Compiling command(queryId=hive_20230906115022_0d6b7c25-9637-4f4c-8432-9425ab2e766f): select * from version limit 1
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:version.ver_id, type:int, comment:null), FieldSchema(name:version.schema_version, type:string, comment:null), FieldSchema(name:version.version_comment, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20230906115022_0d6b7c25-9637-4f4c-8432-9425ab2e766f); Time taken: 2.056 seconds
INFO : Executing command(queryId=hive_20230906115022_0d6b7c25-9637-4f4c-8432-9425ab2e766f): select * from version limit 1
INFO : Completed executing command(queryId=hive_20230906115022_0d6b7c25-9637-4f4c-8432-9425ab2e766f); Time taken: 0.051 seconds
INFO : OK
+-----------------+-------------------------+--------------------------------+
| version.ver_id | version.schema_version | version.version_comment |
+-----------------+-------------------------+--------------------------------+
| 1 | 3.1.1000 | Hive release version 3.1.1000 |
+-----------------+-------------------------+--------------------------------+
1 row selected (2.47 seconds)
0: jdbc:hive2://sdpmaster.litsoft.com.cn:2181>
beeline
beeline -u jdbc:hive2://litsoft.com.cn:10000/default -n hive -p *Hive123
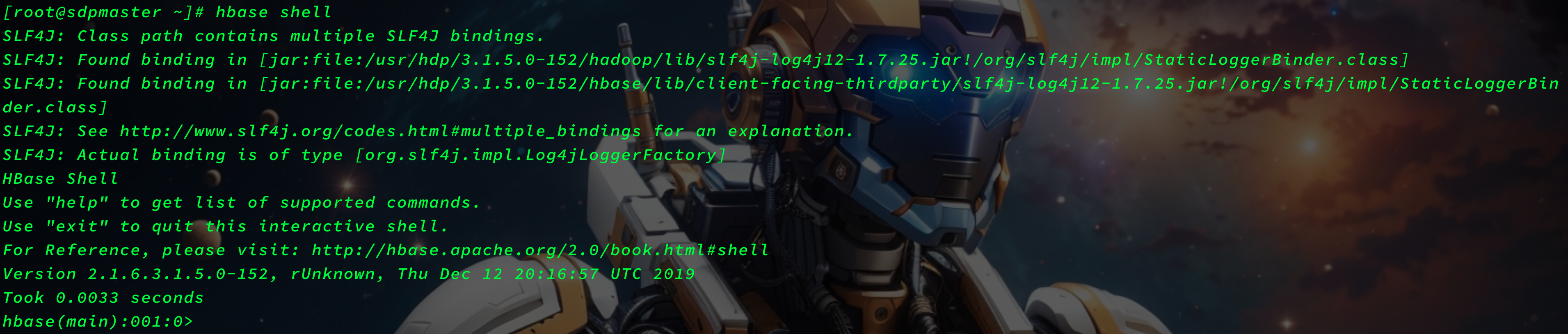
hbase shell
Spark-shell
sudo -u spark spark-shell
val textFile = spark.read.textFile("file:///root/superfile.txt")

Spark-sql
sudo -u spark spark-sql


pyspark
sudo -u spark pyspark
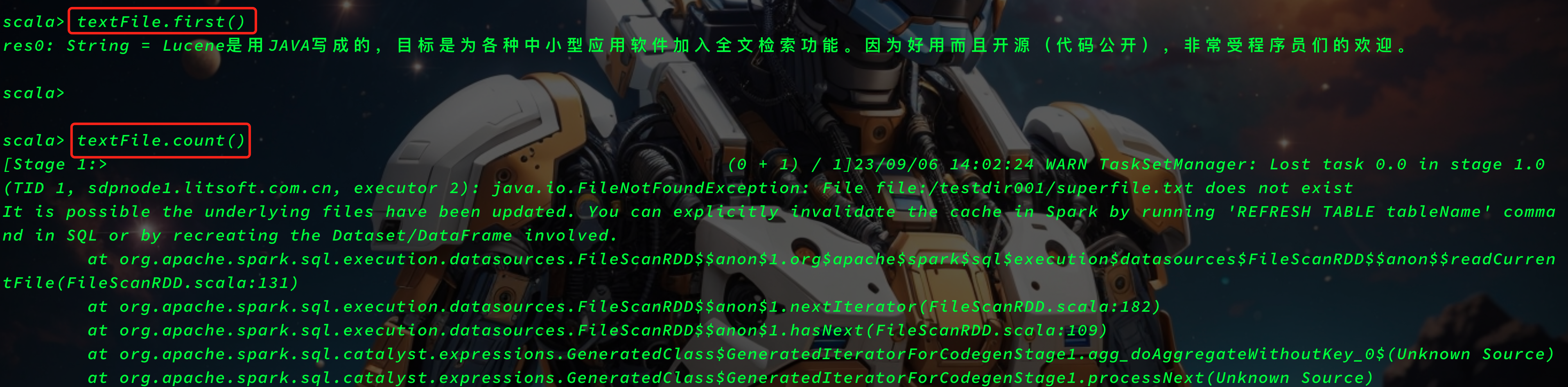
textFile = spark.read.text("file:///testdir001/superfile.txt")
testFile.first()
testFile.count()
Caused by: java.io.FileNotFoundException: File file:/testdir001/superfile.txt does not exist
It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved.


评论区